
모양과 뜻
프로그래밍 언어는 문법구조(syntax)와 의미구조(semantics)로 구성되어있습니다. 문법구조는 언어의 겉 모양이고 의미구조는 언어의 속뜻을 의미합니다.
이 두가지를 정의하지 못하면 언어라고 볼수 없고, 이 두가지를 알지 못하면 언어를 사용할 수 없습니다.
제대로 생긴 프로그램을 어떻게 만들고 그 프로그램의 의미가 무엇인지에 대한 정의가 없이는 언어를 구현할 수 도 없고 사용할 수 도 없습니다.
또, 그 정의들은 애매하지 않고 혼동이 없어야 합니다.
문법구조
문법구조는 프로그래밍 언어로 프로그램을 구성하는 방법입니다. 제대로 생긴 프로그매들의 집합을 만드는 방법으로, 귀납적으로 규칙을 정의합니다.
이 귀납적인 규칙으로 만들어지는 프로그램은 나무(TREE)구조를 갖춘 2차원의 모습입니다.
(여기서 나무라고 표현 했는데, 자료구조의 Tree라고 생각하시면 됩니다.
책에 나무 라고 용어를 풀어서 사용하고 있는데, 아무래도 실제 프로그래밍에서 좀 멀어져서 바라보고자 하는 의도가 있다고 보여집니다.
이 글에서 설명하고자 하는 내용들을 실제로 programming 언어의 특정 알고리즘 차원에서 바라보지 말고 좀 떨어져서 바라보는 것도 나름 의미가 있습니다.)
정수식을 만드는 귀납규칙을 생각해봅시다.

1. 임의의 정수는 정수식이라고 한다.
2.두개의 정수식을 가지고 + 를 이용해 정수식을 만들수 있다고한다.
3. 하나의 정수식을 가지고 -를 이용해 정수식을 만들수 있다.
이와 같은 형식으로 간단한 명령형 언어를 생각해봅시다.

0. E는 위에서 정의한 정수식이라고 하자.
1. skip 만 있는 명령문은 그것만 말단으로 가지고 있는 그것만 말단으로 가지고 있는 나무가 된다.
2. 정수식을 오른쪽에, 하나의 변수를 왼쪽에, 루트는 := 임을 표시하는 나무가 된다.
3. 세계의 나무를 하부나무로 가지고 있고 루트노드에는 "if"문 임을 표시하고 있는 나무가 된다.
4. 두개의 명령어 나무를 하부나무로 가지고 있고 루트 노드에는 순차적인 명령문임을 표시하는 ";" 나무가 된다.
위 규칙들은 읽는 사람을 돕기 위해 필요 이상의 정보가 들어있습니다.
if 와 then, else 이런 단어들이죠. 또 명령어의 순서 역시 마찬가지죠.
이를 필요한 정보만 가지도록 간략화 한다면,


이와 같이 각 규칙마다 간단한 symbol만 있으면 그만이다, then else 같은 장식이 필요 없어집니다.
아니면, 우리가 각 규칙을 구분할 수 있다면, 심볼 조차도 생략할 수 있게 됩니다.


사실, 이렇게 심볼까지 생략해가면서 간소화 시킬 필요는 없지요. 프로그래밍 언어의 사용자는 사람이기 때문에 사람이 이해하는데 도움이 되는 수준으로 규칙을 만들 필요가 있습니다.
그래야 문법 규칙들을 보고 만드는 방법에 대한 힌트가 될 수 있기 때문이죠.
요약된 문법 구조와 구체적인 문법구조
(abstract syntax and concrete syntax)
지금까지 봐온 규칙들은 요약된 문법 규칙이라고도 합니다. 프로그램을 만들때 사용하는 문법은 지금까지 보아온 귀납적인 방법이면 충분합니다. 결과물은 나무구조를 가진 2차원의 구조물이죠.
그러나, 프로그램을 읽을 때의 문법은 더 복잡해집니다. 만들어진 프로그램을 표현할때는 나무를 그리지 않고 일차원적인 글로 표현하게 되고, 쓰거나 말하는 사람의 머리에 그려져 있었을 2차원의 나무구조를 복원시키는 규칙들이 되기 때문입니다.
즉,요약된 문법구조와 구체적인 문법구조의 차이를 표현하자면 , 프로그램을 만들때 사용하는 규칙이냐, 읽을때 사용하는 규칙이냐 하는 차이로 보시면 됩니다.
그렇다면 구체적인 문법은 얼마나 구체적일까?
다음의 정수식을 살펴봅시다.
-1+2
위 정수식은 다음 두개의 나무구조중 하나를 일차원으로 펼친 것입니다.
<<-1>+2> -<1+2>
어느것인가? 프로그램 "-1+2"를 둘 중 어느것으로 복구 시킬 것인가?
이 요약된 문법으로는 어느 구조로 복구 시켜야 할 지 알 수가 없습니다.
정수 문법식이 다음과 같다면 어떨까요?

이 규칙을 좀 설명하면,
음의 부호가 앞에 붙은 정수식인 경우는 2가지 밖에 없습니다.
1. 말단 자연수
2. 괄호가 붙은 정수식
구체적인 문법구조는 혼동없이 2차원의 프로그램 구조물을 복구하는데 사용되는데, 이 문법은 프로그램 복원 또는 프로그램의 문법검증이라는 과정의 설계도가 됩니다.(parsing)
의미구조
문법구조로 1+2를 쓰는 방법을 앞에서 봤다면 1+2가 무엇을 뜻하는가에 대해서 살펴볼 때가 되었습니다.
1+2가 뜻하는 것을 2가지로 분류해서 볼수 있는데요.
1. 결과값 3을 뜻한다.
2. 1과 2를 더해서 결과를 계산하는 과정을 뜻한다.
결과값 3을 의미하는 스타일은 뜻하는 바 궁극을 수학적인 구조물의 원소로 정의해 가는 스타일 "궁극을 드러내는 의미구조( denotational semantics)"라고 합니다.
반면, 프로그램의 계산 과정을 정의함으로서 프로그램의 의미를 정의해 가는 스타일 " 과정을 드러내는 의미구조(operational semantics)" 라고 합니다.
이를 C 언어로 이를 표현해보자면, 아래와 같은 코드일것입니다.
int func_3() { return 1+2;}
void main()
{
int r = func_3(); // denotational semantics
printf("%d",r);
printf("%d",func_3()); //operational semantics
}
그런데 새로운 언어인 ZX 라는 언어가 있다고 합시다. 이 언어의 표현 형식이 operational semantics만 지원한다고 한다면, 아래와 같은 동작으로 이어질 것입니다.
program start;
var x=1+2;
var y=x; // 3이 아닌 1+2라는 연산식을 넘겨줍니다.
display x; // display 에 1+2 라는 연산식을 넘깁니다.
display y; // display 1+2라는 연산 식을 넘깁니다.
program end;
다음 코드도 같이 확인해봅시다.
program start;
var f = ax+b;
x=2;
a = 4;
b=4;
display f; // 4*2+4 라는 연산 식을 display에 넘겨줍니다.
a = 10;
b = 5;
display f; // 10*2+5 라는 연산 식을 display에 넘겨줍니다.
program end;
프로그래밍 언어들은 denotational semantics 와 operational semantics 를 모두 다 제공하고 있고 적절한 상황에서 사용 할 수 있도록 설계되어있습니다.
과정을 드러내는 의미구조(operational semantics)는 어느정도 수준으로 표현해야 할까요?
아주 low 하게 CPU에 전달되는 전기적 신호를 일일이 표시해야 할까요? 아니면 , 1이 1을 계산하고 2가 2를 계산하고 +가 1+2=3이라는 등식을 적용하는 것으로 표현해야 할까요?
아니면 실행되는 과정을 , 프로그램과 그 계산 결과를 결론으로 하는 논리적인 증명 과정이라고 표현해야 할까요?
의미구조를 정의하는 목표에 맞추어 그 디테일의 정도를 정하게 됩니다. 대개는 상위의 수준, 가상의 기계에서 실행되는 모습이거나, 기계적인 논리 시스템의 증멍으로 정의하게 됩니다.
과정을 드러내는 의미구조도 denotaional semantics 처럼 충분히 엄밀합니다.
1. 조립식이 아닐 수 있다: 프로그램의 의미가 그 프로그램의 부품들의 의미로만 구성되는 것은 아니다.
2. 하지만 귀납적이다 : 어느 프로그램의 의미를 구성하는 부품들은 귀납적으로 정의된다. 이 귀납이 프로그매의 구조만을 따라 돌기도 하지만, 프로그램 이외의 것을 따라 되돌기도 한다.
(이 문장들의 의미는 잘 이해 못했습니다.)
프로그램의 실행이 진행되는 과정을 큰 보폭으로 그려보자. <<big-step semantics>>
명령문 C와 정수식 E에 대해서 각각 아래와 같이 정의합니다.

1. 명령문 C가 메모리 M의 상태에서 실행이 되고 결과의 메모리는 M'이다.
2. 정수식 E는 메모리 M의 상태에서 정수값 v를 계산한다.
이에 대한 모든 규칙을 쓰면 이렇습니다.











이 규칙들은 논리 시스템의 증명 규칙이라고 이해해도 됩니다. 명령 프로그램 C의 의미는 임의의 메모리 M 과 M'에 대해서 MㅏC => M' 를 증명할 수 있으면 그 의미가 그 의미가 됩니다.
대개는 M이 비어있는 메모리일때 C를 실행시키는 과정을 나타내고 싶으므로, 0ㅏC=>M' 의 증명이 가능하면 C의 의미가 됩니다.
그것이 증명 불가능 하면 C의 의미는 없는 것입니다.
명령문 C : x:=1 ; y:=x+1;
는 다음과 같은 증명으로 표현된다.

이렇게 의미구조를 정의하는 방법을 자연스런, 구조적인, 혹은 관계형 의미구조라고 부릅니다.
natural semantics, structural operational semantics , relational semantics
1. 자연스런 : 추론규칙 꼴로 구성되어있고, 자연스런 추론 규칙(natural deduction rules)이라는 규칙때문에 이런 이름이 붙었다고 합니다.
2. 구조적: 계산 과정을 드러내는 의미구조 방식은 이전의 방식 보다 더욱 짜임새가 있었기 때문입니다.
- 이전의 방식은 가상의 기계를 정의하고 프로그램이 그 기계에서 어떻게 실행되는지를 정의합니다. 이러다 보니, 기계의 실행과정중에 프로그램이 부자연스럽게 조각나면서 기계 상태를 표현하는 데 동원되기도 하고, 프로그램의 의미를 과도하게 낮은 수준의 실행과정으로 세세하게 표현하게 됩니다.
이런 방식을 구현을 통해서 정의하기(definition by implementation) , 어떻게 구현하는지 보임으로서 무엇인지 정의하기 라고 합니다.
프로그램의 구조마다 추론 규칙이 정의되고, 계산과정은 그 추론규칙들을 결합하여 하나의 증명이 되는 것입니다.
- 의미규칙들이 한 집합을 귀납적으로 정의하는 방식이고 , 그 귀납이 프로그램이나 의미장치들의 구조를 따라 흐르기 때문입니다.
프로그램의 실행을 작은 보폭으로 정의해보자 <<small-step semantics>>












이 과정을 변이과정 의미구조(transition semantics) 라고도 합니다.
이 과정에서는 문법적인 부분들과 의미적인 부분들이 한데 섞이고 있습니다.
전통적으로는 것 모양을 구성하는 것과 속 뜻을 구성하는 것은 반드시 다른세계에 멀찌감치 떨어져 있어야 하지만, (Tarski :수학자가 시작한 전통)
문제될 것 또한 없습니다.
프로그램 이외의 의미장치 없이 프로그매만을 가지고도 변이과정 의미구조를 정의 할 수 있습니다.
예를 들어 메모리를 뜻하는 M이라는 프로그램이외의 의미장치 없이, 1+2+3 을 다시 쓰면 3+3 다시쓰면 6 으로 프로그램 이외의 다른 장치가 사용되지 않습니다.
위의 1+2+3 을 3+3으로 다시 6으로 다시 써 가는 과정이 프로그램의 실행과정과 같습니다.
이 경우 어느 부분을 다시 써야 하는가?, 다시 써야 할 부분을 무엇으로 다시 써야 하는가 ? 하는 것에 대한 정의가 필요합니다.
어느 부분을 다시 쓸것인가 하는 것은 실행 문맥(evaluation context)에 의해서 정의됩니다.
실행 문맥의 정의에 따라서 프로그램을 구성하다 보면, 다시 써야할 부분이 결정됩니다. 그 정의가 문법적으로 가능합니다.
실행 문맥을 가지고 있는 프로그램 K를 정의합니다.
K 안에는 [] 딱 하나가 있습니다. 그 곳이 프로그램에서 다시 써야할 부분, 먼저 실행되어야 할 부분이 됩니다.
이런 특징을 강조하기 위해서 "K[]" 라 쓰고, 그 빈칸에 들어있는 프로그램 부분 C까지 드러내어 "K[C]" 라고 표현합니다.
이 형식은 아래와 같은데요.

1. 지정문, 대입 처리에서 실행되어야 할 부분은 K는 오른쪽 식이고 x:=K
2. 순차적 처리 구문 에서 명령문이 다음에 실행되어야 할 부분이라면, 앞의 명령문은 시행이 이미 끝났을 때 만이고, done; K
3. 덧셈 식에서 오른쪽 식이 다음에 실행되어야 할 부분 이라면, 왼쪽 식의 결과는 나와 있어야 한다. v+K
위의 문법적인 표현을 다시쓰기 규칙을 정의하면, 아래와 같습니다.

그릭 속에서 어떻게 다시쓰이는가 하면, 즉,위의 규칙이 어떻게 동작하는지 보면,









x:=1 ; y:=x+1
의 의미를 위의 문맥구조로 풀어보면,
1 )

2)

3 )

4 )

5)

이러한 과정으로 풀이된다.
C : 명령문
M: 메모리
K: 실행 문맥
가상의 기계를 통해서
프로그램의 의미는 어떤 가상의 기계(virtual machine)가 정의되어있고 그 프로그램이 그 기계에서 실행되는 과정으로 나타나게 됩니다.
기계에서 실행되는 과정은 기계상태가 매 스탭마다 변화되는 과정이 됩니다.
예를 들면, 정수식의 의미가 한 게계의 실행과정으로 다음과 같이 정의됩니다.
변수가 없는 정수식만을 생각해보면,

이는 소위 말하는 "스택머신 (stack machine)" 입니다. 이 기계는 스택 S 와 명령어 C 로 구성되어있습니다.

스택은 정수들로 차곡 차곡 쌓여있습니다.

명령어들은 정수식이나 그 조각 들이 쌓여있습니다.

기계 동작 과정의 한 스텝은 다음과 같이 정의됩니다.




<S,n.C>\quad\rightarrow\quad<n.S,C>\\
<S,E_1+E_2.C>\quad\rightarrow\quad<n.E_1\cdot E_2,+,C>\\
<n_2.n_1.S,+.C>\quad\rightarrow\quad<n.S> \quad\quad(n=n_1+n_2)\\
<n.S,-.C>\quad\rightarrow\quad<-n.S,C>
정수식 E의 의미는 <e,E> --> .... 입니다.
정수식이 아닌 우리가 프로그래밍에서 사용하는 command 형식으로 다시 정의해보면 아래와 같습니다.

그리고 , 기계 작동과정도 다음과 같이 정의 됩니다.
<S,push n.C> --> <n.S,C>
<n.S,pop.C> --> <S,C>
<n1.n2.S,add.C> --> <n.S,C> (n = n1+n2)
<n.S,rev.C> --> <-n.S,C>
그리고 스택 머신 안에서 정수식들은 다음과 같은 변환됩니다.
[[n]] = push n
[[E1+E2]] = [[E1]].[[E2]].add
[[-E]] = [[E]].rev
이러한 기계의 과정이 매우 임의적이라 생각될수 있습니다. 가상의 기계를 어떻게 디자인 하는가? 그 기계의 디테일은 어느 레벨에서 정의해야 하는가?
그 대답은 프로그램의 의미를 정의하는 목적, 그에 따라 결정될 것이다.
[내 생각] 프로그래밍 언어가 어떤 래벨에서 정의되는 가가 프로그램이 돌아가는 환결과 시스템을 정의하는데 기준이 될것입니다. 프로그래밍 언어가 컴퓨터 system 에서 동작하는 프로그램을 작성하기 위한 용도이기 때문에, 프로그래밍 언어의 syntax나 semantic이 메모리에 한정되어 설계됩니다. 만약 프로그래밍 언어가 인터넷의 서비스나 인프라위에서 프로그램을 작성하기 위한 용도로 개발되었다고 한다면, 이때도 물론 임시적인 memory를 정의될 필요가 있지만, 훨씬 큰 의미로 접근 하게 됩니다. file open , memalloc, socket 등 local system에 대한 정의도 필요할지도 모르겠지만, 이런 레벨의 환경과 리소스를 접근하는 인터페이스는 아예 생략(숨기고)하고, openUrl, connectSite, httpRequest 등의 internet 리소스에 접근하기 위한 용도의 명령어들로 서비스 구축을 위한 언어를 설계 할 수 있을 것이라 생각됩니다. (Java script 처럼 말이죠) 또 다른 예를 들면, 어떤 프로그래밍 언어로 표현 하고 싶은 것이 "지구" 라는 행성이라고 하고 지구의 자원들을 다루는 프로그래램을 개발 한다고 하면, 우리가 생각하는 프로그래밍 언어와는 모양이 많이 달라 질 수도 있습니다. 파일이나, 메모리, URL , WEB, HTTP 이런 용어나 computer level의 명령어가 아닌, 지구상의 객체들을 query 하고, 해당 객체에 메세지를 전달하고, 어떤 행동을 요구하고, 그에 대한 응답을 받고, 하는 형식의 명령어들로 정의 되지 않을까요? 언어에는 표현 되지 않았지만, 그 밑에는 수많은 sub system들이 존재 하겠죠. GPS, WIFI, 각 객체들을 식별하기 위한 인식 장치, 모니터링 장치, 대상을 알 수없는 경우 모르는 대상에 대한 처리 시스템, 인력 관리, 수행에 필요한 지불 시스템... 등등.. 하지만 언어에는 이런 서브시스템에 대한 내용이 표시 되지 않아도 된다면 더없이 편한 "지구 관리 프로그램"을 작성 할 수 있는 도구가 되겠죠. (영화에서 많이 보던 시스템인데, 만약 프로그래밍 언어가 이런 래밸로 개발된다면, 가능 할 것도 같군요. 현장에 요원을 투입하고, 회사를 설립하고,)
|
대개 가상 기계를 사용해서 프로그램의 의미를 정의하는 것은 프로그래밍 언어를 구현하는 단계에서 사용됩니다: 프로그래밍 언어의 번역기나 실행기를 구현할때 말이죠.
프로그래밍 언어의 성질을 굴이하거나 그 언어로 짜여진 프로그램들의 관심있는 성질을 분석할 때에 사용하는 의미구조로 사용되는 예는 드뭅니다.
가상 기계는 대개가 이와 같은 분석에서는 필요하지 않은 디테일을 드러내기 때문입니다.
기계중심의 언어로 빨리 넘어가고 싶기 때문에, 다음 내용들에 대해서는 현재는 생략 합니다. 다음에 기회가 되면 정리하도록 하겠습니다.
- 궁극을 드러내는 의미 구조 (denotaional semantics)
- 조립식일 수 있는 이유(의미공간 이론 : domain theory)
- CPO, 연속함수, 최소고정점
다음 >>기계중심의 언어
'개발 Note > 값 중심의 언어' 카테고리의 다른 글
| 감명 깊었던 programming language principles 4- 기계 중심 언어- 타입시스템 (1) | 2014.12.09 |
|---|---|
| 감명 깊었던 programming language principles 4- 기계 중심 언어-메모리 관리 (0) | 2014.12.04 |
| 감명 깊었던 programming language principles 4- 기계 중심 언어 (0) | 2014.12.03 |
| 감명 깊었던 programming language principles 2-기본기 (4) | 2014.11.12 |
| 감명 깊었던 Programming language principles 1 컴퓨터는 프로그래밍 언어에서 시작되었다. (0) | 2014.11.11 |































 (R1)
(R1)  (R2)
(R2)  (R3)
(R3)  (R4)
(R4) (R5)
(R5)  (R6)
(R6) (R7)
(R7)  (R8)
(R8) (R9)
(R9)  (R10)
(R10) (R11)
(R11)  (R12)
(R12) 의 증명을 위의 증명규칙으로 만들면 아래의 나무 구조가 됩니다.
의 증명을 위의 증명규칙으로 만들면 아래의 나무 구조가 됩니다. 
 의 f는 모두 참인가? 반대로, 참인 식들은 모두 위의 증명규칙들을 통해서
의 f는 모두 참인가? 반대로, 참인 식들은 모두 위의 증명규칙들을 통해서 

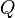 는 유한하고 비어있지 않은 상태들의 집합
는 유한하고 비어있지 않은 상태들의 집합 는 유한하고 비어있지 않은 기호와 알파벳들의 집합
는 유한하고 비어있지 않은 기호와 알파벳들의 집합 는 비어있음을 알려주는 기호 (테이프 위에서 유일하게 무한하게 나타날 수 있는 기호)
는 비어있음을 알려주는 기호 (테이프 위에서 유일하게 무한하게 나타날 수 있는 기호) 는 입력가능한 기호들의 집합
는 입력가능한 기호들의 집합 는 초기상태
는 초기상태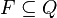 는 최종상태, 또는 수락 상태
는 최종상태, 또는 수락 상태 는 부분함수
는 부분함수